
DADOS VINCULADOS E ALGUNS LIMITES DA CATALOGAÇÃO BIBLIOGRÁFICA
Tão revolucionário e inovador como o desenvolvimento da Web Semântica, tem sido o ambiente catalográfico, nos últimos anos. É uma evolução transformadora, agora impulsionada pelo conceito dos dados vinculados (linked data) ou dados abertos vinculados (linked open data – LOD).
A infraestrutura bibliotecária altera-se à medida que os princípios básicos do que coleta e como coleta, organiza e disponibiliza, são repensados. Neste aspecto, o bibliotecário de catalogação precisa ter claro o que são dados vinculados, e como impactam a sua atividade, ao potencializar a exploração de um ambiente de descoberta global.
Ressalte-se que a Web Semântica é os dados vinculados em um novo contexto, no qual as bibliotecas, entre outras organizações de informação, podem oferecer serviços baseados nos dados abertos, e no qual sistemas de informação inovadores podem ser projetados. Como as possibilidades e aplicações são amplas, profissionais da informação devem dedicar atenção.
Afinal, o potencial dos dados vinculados decorre de estarem embutidos na estrutura da Web semântica. À medida que aspectos crescentes de nossa vida social, privada e profissional se movem para a nuvem, a maneira como as informações são armazenadas e conectadas na Web se torna crucial. Os dados vinculados, definidos por Tim Bernes-Lee, apresentam quatro princípios, básicos:
- URIs (Uniform Resource Identifiers) para nomear recursos na Web;
- URIs HTTP para encontrar recursos;
- uso de padrões (RDF, SPARQL) para fornecer informações por link; e
- estabelecer links para outros URIs para descobrir informações relacionadas.
Em geral, dados vinculados são publicados com uso do RDF (Resource Description Framework). A expressão RDF é constituída de sujeito, predicado e objeto. Apesar de uma estrutura simples, torna possível fornecer afirmações sobre qualquer coisa, por exemplo, a obra: Capitães da Areia (sujeito), tem autor (predicado), Jorge Amado (objeto).
Idealmente, sujeito e objeto podem ser representados por URIs (uma cadeia de caracteres usada para identificar um nome ou um recurso na Web). Exemplo:
https://lccn.loc.gov/39015889 (sujeito),
tem autor (predicado), [mesmo o predicado pode ser indicado por URI]
https://lccn.loc.gov/n50024126 (objeto)
A própria instrução pode ser expressada em uma sintaxe em XML, permitindo aos sistemas aplicativos trocarem informações, na web, sem perda de significado. Como o RDF é um modelo popular, as informações expressas podem ser usadas por variados sistemas. Outro aspecto do RDF é o de ser um modelo de entidade e relacionamento. Como tal, está adaptado para servir de base aos modelos entidade-relacionamento atuais. O ponto forte é possibilitar que duas entidades sejam ligadas e, através deste processo, uma imensa e rica rede de dados é criada.
Considerar que os dados vinculados usam a Web para estabelecer conexões entre dados de diferentes fontes, mantidas por duas ou mais organizações; ou simplesmente sistemas heterogêneos existentes em um mesmo local.
Ressalte-se a inexistência de garantia de afirmações verdadeiras (por exemplo, "Capitães de areia tem autor Fernando Modesto" é afirmativa válida em RDF, como " Capitães de areia tem autor Jorge Amado"), porém afirmações inválidas podem ser corrigidas por qualquer pessoa. Esse processo iterativo de uso e correção, torna a Web mais rica e confiável. E isto é denominado de "contribuição coletiva" (crowdsourcing), em âmbito global.
Philip Evan Schreur, ao tratar da revolução dos dados vinculados, destaca que desde os tempos dos catálogos em fichas, as bibliotecas concentram-se nos registros bibliográficos, até pelo fornecimento de metadados com informações sobre as coleções. A estrutura dos registros sempre foi cuidadosamente elaborada, e os pontos de acesso como nomes, assuntos e títulos advinham de tesauros e bases de autoridade controlados. Mesmo com a transição dos catálogos impressos, para os catálogos online, possibilitada com o desenvolvimento do Formato MARC, na década de 1960, o foco do bibliotecário de catalogação permaneceu nos registros.
As informações contidas nos registros em MARC dividem-se em campos e subcampos; e são armazenados em bancos de dados. Subsidiados por teorias e práticas bibliográficas. A possibilidade de organizar e recuperar os recursos eficazmente, por meio da descrição, análise e classificação controladas parecia alcançável enquanto as bibliotecas lidavam com informações finitas, em um sistema bibliográfico fechado.
O sistema integrado de bibliotecas (ILS) foi desenvolvido para aproveitar os processos técnicos dentro das áreas operacionais da biblioteca (aquisição, catalogação, circulação, etc.), e utilidades bibliográficas como OCLC e SkyRiver, que auxiliam no intercâmbio de registros.
Esforços colaborativos como o Program for Cooperative Cataloging (PCC) e programas promovidos pela American Library Association (ALA) ajudam as bibliotecas a manterem uma padronização na qualidade dos seus dados, para desempenho das atividades.
Entretanto, o foco nos registros bibliográficos tem inconvenientes. Primeiro, há agências que privilegiam a própria versão de registro em suas bases locais, alterando a cópia bibliográfica fornecida pela utilidade bibliográfica, ou ausentando elementos, nas práticas catalográficas de elaboração dos registros, para os usuários. Lembrando que, nesta discussão, há o alto custo dos serviços catalográficos, influenciado pelo número de funcionários dedicados, e pela manutenção do crescente volume de registros. Conforme a Lei de Ranganathan, “A biblioteca é um organismo em crescimento”.
O segundo inconveniente refere-se ao banco de dados bibliográfico ser um sistema fechado. Para o usuário descobrir um recurso, no catálogo online, o registro bibliográfico buscado deve estar presente no sistema. Entretanto, os registros de recursos que a biblioteca possui podem nunca aparecer no catálogo, se houver falta de pessoal para cria-los ou incorreções na sua inclusão. Ao considerar a quantidade de recursos existentes na Web, o problema cresce em magnitude.
Dados vinculados não são focados em registros bibliográficos, mas em declarações específicas. Assim, nenhum registro precisa ser mantido em um ILS local, ou banco de dados global. Em vez disso, coleções descritas em RDF são suficientes. Os dados vinculados liberam as bibliotecas do ciclo de criação, manutenção e exclusão de registros. Um tempo valioso do bibliotecário de catalogação é liberado, bem como as limitações de um catálogo.
Saliente-se que as bibliotecas passaram décadas selecionando com acuidade os recursos adicionados às coleções. Esse processo de curadoria concentrou os acervos às necessidades das comunidades, dando às coleções um ponto de vista único. Desta forma, os registros catalográficos locais refletem as necessidades de descoberta destas comunidades, um ciclo ligando aquisição e acesso. No entanto, o processo catalográfico local pode tornar-se falho, pois partes das coleções podem não aparecer detalhadas no catálogo. Bibliotecas podem criar bases de dados sob variados formatos descritivos para acessar coleções distintas, mas ao fazer isso isolam o conteúdo de descobertas mais amplas.
Outro aspecto, são os fornecedores que favorecerem a compra de volumosos pacotes genéricos de e-books, promovem a quebra do ponto de vista de uma coleção. Agências bibliográficas também podem optar por carregar grandes quantidades de livros digitais livres de direitos autorais (como os disponíveis no HathiTrust – biblioteca digital de livros e periódicos), tornando as coleções mais genéricas. Desta maneira, os vínculos da comunidade com as coleções refletidas no catálogo local, enfraquecem.
Bibliotecas também têm explorado meios de integrar os registros bibliográficos diretamente aos ambientes de dados, para descoberta aprimorada. No entanto, esses metadados, por vezes, não são padronizados, ou são adaptados a uma coleção específica. Além de não se integrarem bem no contexto do catálogo tradicional. Ao mesclar coleções, as bibliotecas podem unir silos de informações, mas as opções de metadados inconsistentes, as isolam, no âmbito dos dados abertos globais.
As informações substanciais crescem na Web. Os usuários há muito mudaram e solidificaram suas buscas no ambiente digital. A indexação de registros bibliográficos por mecanismos de busca, aumentam a chance de encontrá-los; mas nenhuma chance de encontrar dados da Web, nos catálogos bibliográficos.
Esse movimento dos usuários, segue discutido na área. Apesar de as bibliotecas passarem tempo mantendo suas coleções, e cuidar com esmero dos registros catalográficos. As coleções ficaram menos distintas e os dados da Web tornaram-se mais difundidos. A descoberta voltou-se para fora. Assim, para as bibliotecas atenderem às necessidades do público, via descoberta abrangente, precisam superar os limites dos catálogos, integrá-los com a Web.
Em geral, bibliotecas se concentram no conteúdo dos acervos, por limitações financeiras. É preciso selecionar com cuidado, considerando necessidade atual e futura. Adquirido o ativo, é preciso torná-lo detectável. Para isso, colaboram o uso de processos bibliográficos de descoberta, como pontos de acesso controlados e representações descritivas consistentes. Evita-se que o esforço seja inútil.
Ainda que os processos procedam, eles empalidecem diante dos próprios recursos tratados. Por exemplo, a entrada para o título da série não dá indicação sobre a infinidade de conteúdos importantes relacionados. Mesmo para monografias em um ou vários volumes. É nisto que os modelos conceituais e ontologias atuais exploraram.
Até os editores de e-books podem oferecer certa flexibilidade ao atribuir ISBNs a capítulos, parágrafos, gráficos ou outras partes de uma manifestação, no caso de venda separada. Mas essas partes precisam de metadados descritivos para sua descoberta. Neste sentido, bibliotecas procuram fornecedores aprimorados para os recursos adquiridos. Exemplo é a Nielsen Bookdata Service que disponibiliza tabelas de conteúdo, capas de livros, biografias de autores, resenhas e informações promocionais. Esses dados aprimorados alimentam ferramentas de pesquisa mais elaboradas, e que dão aos usuários novas alternativas de descoberta e de avaliação da qualidade do conteúdo de um recurso.
Todo esse conteúdo adicional pode ser problemático. Desafia o conceito tradicional baseado no AACR2. A exibição em tela, no geral, replica a ficha do catálogo. A RDA permite pensar novo design e uso de dados aprimorados, diante do ambiente de descoberta.
Na catalogação tradicional apenas uma quantidade selecionada de informações é exibida. Como a maior parte é apresentada a partir de dados codificados em MARC/AACR2, para comunicar informações geradas como fichas catalográficas, a exibição carrega a percepção dessas limitações. Muitos dos aprimoramentos bibliográficos atuais com RDA, não têm lugar nas regras da AACR2, e pouco no formato MARC, neste último com a exibição de conteúdo sendo desafio. Afinal, escolhas devem ser feitas para acomodação das informações tradicionais e dos dados aprimorados. Há o risco de os usuários acharem multiplicidade de dados mais irritantes do que úteis.
Além da descrição de recursos tradicionais com dados aprimorados, as bibliotecas têm muitas fontes de conteúdo inexploradas. Exemplo citado por Schreur, envolve a pesquisa dos alunos de um curso de paleografia. Como projeto, cada membro da classe escolhe um fragmento de texto em um manuscrito não identificado e disponível na coleção da biblioteca. O aluno deve identificar conteúdo desse fragmento, identificar o estilo de escrita e indicar uma data aproximada de sua criação. Ao longo do tempo, uma quantidade de estudos foi gerada sobre esses fragmentos de manuscritos; mas todos esses dados estão presos aos relatórios gerados. Esses dados podem ser de grande ajuda aos estudiosos dos fragmentos, até para combiná-los com fragmentos de outras coleções. Mas a menos que tais arquivos impressos sejam solicitados, ninguém nunca os verá. Esta pequena situação dá a dimensão e riqueza das informações criadas. Levanta questões sobre como os dados devem ser disponibilizados? Elaborar registros catalográficos, para cada projeto de cada classe, apesar de simples criação pelo AACR2, seria processo trabalhoso pelo volume, e pouco eficaz na descoberta. Ademais, os registros mal representariam a profundidade das informações contidas nos relatórios. E, a descoberta torna-se o fator crucial e quantidade de registros criados podem não ser a resposta.
Neste contexto, os metadados são essenciais ao ambiente de descoberta e vêm em várias roupagens. As editoras comunicam informações da indústria editorial pelo padrão ONIX (complexo como o MARC). Além do comércio livreiro, há os esquemas bibliográficos, como: Dublin Core, Metadata Object Description Schema (MODS), e Bibliographic Framework Initiative (BIBFRAME) entre outros.
Destaque-se que um substituto para o MARC tem sido buscado com o BIBFRAME, desde 2011. A iniciativa é projetada para colher os benefícios da evolução tecnológica no compartilhamento de dados e a redução de custos de catalogação. Um dos principais requisitos para essa iniciativa é aplicação de dados vinculados, com URIs. A transição para um formato de intercâmbio com adesão de comunidades, além dos limites das bibliotecas, que apresente compatibilidade com outros formatos de comunicação e de compreensibilidade semântica em um ambiente de dados vinculados é o desafio que o mundo das bibliotecas enfrenta.
Os metadados podem ser incorporados em documentos da Web, por meio de um conjunto de extensões no nível de atributo do XHTML, modelado pelo conjunto de expansões do RDFa. Saliente-se que, nas abreviações do RDF, encontra-se a sigla RDFS e suas variações, representando o conjunto de classes e propriedades usado para estruturar o vocabulário do modelo.
Os editores de bases de dados podem desenvolver seus próprios formatos para o contexto dos dados. No âmbito bibliotecário segue-se fortemente com registros em MARC, apesar da perspectiva de novos esquemas.
No ambiente dos dados vinculado, registros MARC são vistos como fonte primária de informações. O esforço bibliotecário colocado no acesso controlado por assunto, responsabilidade, classificação e títulos, tornou os registros desejáveis. Qualquer abordagem sobre biblioteca e dados vinculados, passa pela análise dos registros em MARC. É importante examinar esse formato.
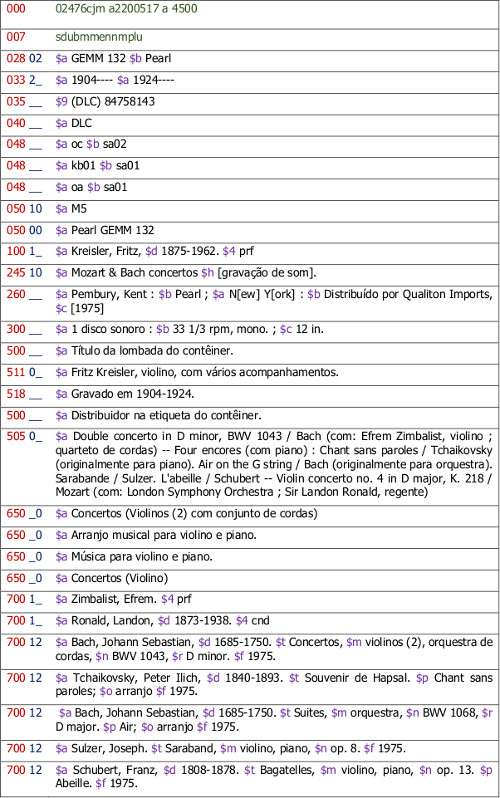
Os quadros 1 e 2 oferecem, respectivamente, um registro MARC e uma representação de gravação de som. Foram extraídos e adaptados do catálogo da Library of Congress e do texto de Schreur. Os quadros fornecem uma descrição do meio, do conteúdo, dos períodos de execução, dos assuntos controlados e das entradas analíticas, para as obras musicais individuais. Tudo exibido em uma estrutura legível a humanos (quadro 2). Desta forma, é apresentado ao usuário a gravação de Fritz Kreisler executando uma seleção de músicas para violino. As obras e responsabilidades são indicadas no suporte, como um todo.
Quadro 1 – Registro MARC de uma Gravação Sonora
 |
 |
No quadro 1, tem-se a codificação do registro em MARC, com os dados separados em entrada principal e secundárias; a representação descritiva da manifestação da obra, e respectivas notas de conteúdo não estruturadas. A codificação em MARC é em realidade um texto eletrônico.
Quadro 2 – Registro do MARC em formato de ficha bibliográfica eletrônica
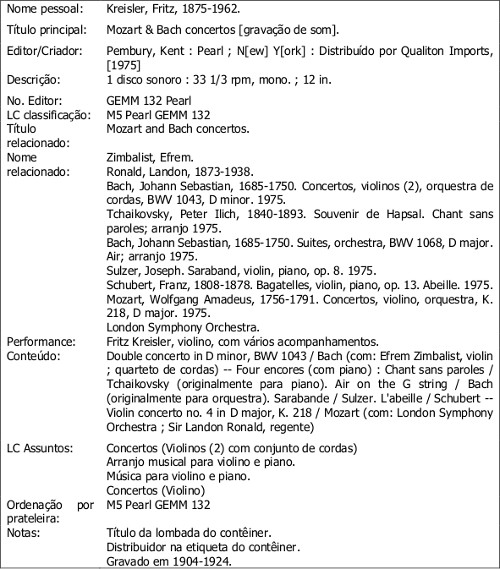 |
No exemplo dos quadros 1 e 2, muito do significado semântico deriva do registro como um todo. Pela leitura do quadro 2, o usuário pode identificar a entrada principal para Fritz Kreisler, que é um violinista.
Também, que a peça de Joseph Sulzer é para violino e piano; e o concerto para violino de Mozart e de Bach é acompanhado pela London Symphony Orchestra, regida por Sir Landon Ronald.
Além disso, se o usuário gostar da composição de Sulzer, pode seguir o assunto "Música para violino e piano" para encontrar obras semelhantes, relacionadas sob mesmo cabeçalho.
A dependência do registro completo para o significado semântico é um resquício do catálogo de fichas, baseado no AACR2. O formato MARC possibilitou que os registros fossem transformados em documentos eletrônicos e compartilhados, mas ainda são registros estáticos e, para serem compreendidos, devem ser analisados por completo.
Afirmações individuais como "Fritz Kreisler, violino, com vários acompanhamentos" ou "Gravado em 1904-1924" não têm sentido fora do contexto do registro.
No entanto, o RDF é um modelo que permite criar declarações independentes. Porém, publicar registros MARC como triplas RDF tem dois obstáculos. Primeiro é o próprio conceito de registro bibliográfico, baseado no impresso. Segundo é a incapacidade do formato MARC de transmitir com clareza o significado semântico dos dados, até por estar apoiado no primeiro obstáculo.
Observa-se, pelo campo do autor, que Fritz Kreisler consta como criador e, pela nota de performance, que é violinista. Visualiza-se que a gravação inclui a colaboração de Efrem Zimbalist e, pela nota de conteúdo, ele é violinista.
Na nota de conteúdo, consta que Kreisler executa uma peça de Tchaikovsky ("Chant sans paroles"), originalmente composta para piano. A partir dos verbetes analíticos adicionados, a peça é da obra "Souvenir de Hapsal", de Tchaikovsky. Nos cabeçalhos de assunto, o termo extraído da Library of Congress Subject Heading (LCSH) para a obra é "Arranjo musical para violino e piano".
O formato MARC foi exitoso em, inicialmente, codificar registros para catálogos impressos. Também, ao transformar os registros em um formulário eletrônico, contribuindo para desenvolver o ILS, o OPAC, programas como o PCC e as utilidades, como a OCLC. Porém, a restrição é o uso exclusivo pelas bibliotecas. Se elas buscam abranger a variedade dos dados gerados em suas instituições e, mesmo no mundo, precisam transcender este formato. No mundo semântico dos dados vinculados, registros MARC são inarticulados, ainda que se tentem forçar adaptações.
Mas por que dados vinculados? Segundo o documento “Report of the Stanford Linked Data Workshop”, de 2011, é uma questão em debate. O ponto interessante são as indicações de valor dos Linked Open Data (LOD), como:
- Colocar informações onde as pessoas procuram: na Web.
- Expandir a capacidade de descoberta de conteúdo.
- Oportunizar a inovação criativa em pesquisa e participações digitais.
- Permitir a melhoria contínua dos dados.
- Criar um armazenamento de dados acionáveis por máquina nos quais serviços aprimorados podem ser elaborados.
- Facilitar alternativas aos silos de domínio da biblioteca.
- Fornecer acesso direto aos dados de maneiras inovadas, não possíveis atualmente, e
- Propiciar benefícios ainda imprevistos e surjam com a expansão da LOD.
Com a Web servindo de ponto de descobertas, os recursos da biblioteca precisam estar lá, representados. Embora os registros catalográficos apareçam na Web, os mecanismos de busca tratam a codificação MARC como mero bloco de texto. Formatos em triplas RDF carregam significado semântico para processamento de máquina. Assim, cada elemento bibliográfico poderia ser registrado como URI, que vincularia esses pontos a outros pontos correspondentes na Web de dados.
Caminham neste sentido, os vocabulários das norma RDA (Resource Description and Access); ISBD (International Standard Bibliographic Description), por exemplo, que foram publicados no Open Metadata Registry, tornando o conjunto de seus elementos e vocabulários em valores disponíveis para uso na Web.
Da mesma forma, a Library of Congress tornou disponível no id.loc.gov – Linked Data Service, acesso interativo e por máquina às ontologias comumente usadas, os vocabulários controlados e outras listas para descrição bibliográfica, aplicado ao novo contexto.
Através da conversão de registros MARC em triplas RDF resolúveis por máquina, o significado semântico dos registros pode ser percebido em instruções individuais. Ao mover essas instruções para a Web, os dados se tornam uma parte vital e estrutural da Web Semântica.
Como os dados vinculados são independentes de formatos, qualquer esquema como Dublin Core (DC), Metadata Object Description Schema (MODS) pode ser convertido em LOD. Neste contexto, os silos eletrônicos de dados, constituídos nas últimas cinco décadas, podem ser desmembrados. E, os dados postos na Web, geram expectativas de ficarem disponíveis para correção ou melhoria.
Se as bibliotecas caminham para além de seus limites, expandindo os seus dados para Web, possibilitam acesso e atração ao público.
Ademais, elas deixam de ser um tipo de banco de dados relacional fechado, para algo amplo, quase infinito. Neste sentido, o desenvolvimento de modelos conceituais, ontologias, protocolos e normas, se direcionam, como aplicação necessária à reunião de informações em domínios utilizáveis, ou seja, subáreas de conhecimento que possam ser exploradas a critério do usuário.
Enfim, as bibliotecas ao se moverem para o ambiente dos dados vinculados, têm o poder de alterar a maneira de criar, manter e explorar seus dados bibliográficos. Nesta perspectiva, o trabalho do bibliotecário de catalogação segue em contínua mudança. E, a simples ideia de criar metadados para recursos informacionais e associá-los a um banco de dados para descoberta torna-se coisa do passado.
Indicação de leitura:
Berners-Lee, T. Linked data – desing Issues. 2006. Disponível em: https://www.w3.org/DesignIssues/LinkedData.html
Report of the Stanford Linked Data Workshop, 27 June – 1 July 2011. Disponível em: https://www.clir.org/pubs/reports/pub152/stanford-linked-data-workshop/
Schreur, P. E. The Academy Unbound: Linked Data as Revolution. LRTS, vol. 56, n. 4, p. 227-237, 2012.